TOC
etcd QoS Feature Design(draft)
- status: in progress.
- create date: 2020-03-30(draft)(tangcong)
- updated: 2020-09-14, DbUsedBytes optimzed to PercentOfStorageQuotaUsed,thanks piotr tabor.
- update: 2020-09-16, add related work,thanks joe betz.
- update: 2020-09-16, add thoughts on decomposing the rules(piotr tabor)
- update: 2020-09-17,add faq, simplify qos rule(tang cong)
- update: 2020-09-18,list detailed Goals/Non-Goals/Future Goals.(tang cong)
Background
As the metadata storage of kubernetes, etcd, stability is extremely important. However, at present, etcd will consume a lot of CPU, memory, and bandwidth resources in the face of some highly concurrent expensive read / write requests, resulting in high service load, even OOM, etc. Common expensive requests such as full keyspace fetch, a lot of event queries(list event), a lot of pod queries(list pods), a lot of crd queries(list crd), and a lot of configmap writes.
In fact, expensive requests may be common. some newbies will not follow the best practices of k8s. Some of their services are only deployed in one namespace with thousands of pods, and some will write tens of thousands of custom resources to the same namespace, and some write a large number of events when the service is abnormal. if there are too many resources in one namespace, get resources through the label, or list all resources, it may cause etcd memory and load to increase.(apiserver is not the only client, but it is the most typical, so the examples I give are related to apiserver. Clients in other scenarios such as configuration center, service discovery, and scheduling services also have the same problem)
At the same time, etcd currently has only an extremely simple speed limit protection. When etcd’s committed index is greater than the applied index threshold is greater than 5000, it will reject all requests and return the error ErrTooManyRequests. Therefore, its shortcomings are obvious, it is impossible to accurately limit the speed of expensive read / write requests, and it cannot effectively prevent the cluster from being overloaded.
Therefore, I hope to implement a QoS feature that allows users to set the maximum qps under different paths and grpc methods, and can automatically identify expensive read / write requests and limit their speed to prevent etcd overload and further improve etcd cluster Stability.
Goals
- Provide a mechanism to match and limit expensive requests to prevent etcd performance degradation or even OOM, unavailability. (P0)
- Prevent etcd from being unwritable due to a large number of unimportant data being written(such as events).(P1)
- Provide very simple rate limiting capabilities for multi-tenant scenarios.(P2)
- Support the configuration QoS rules based on multiple attributes and conditions (such as operations(RangeRequest,PutRequest,DeleteRequest,Authenticate), key prefix, caller user, percentOfStorageQuotaUsed, traffic, NumberOfKeyScan, latency).
- Support multiple queue discipline kind/shaping algorithms(such as token bucket filter, leaky bucket filter), with good scalability.
- Different QoS rules support the configuration of different queue discipline, priority. if a request satisfies multiple rules, the rule with the highest priority is selected.In general(except the used db size is close to quota), non-expensive requests are not subjected to any rules by default.
- The cpu and memory consumption of the QoS feature can be controlled without significantly reducing the etcd server performance.(P0)
Non-Goals
- QoS rules do not apply to the entire cluster, but to every node.
- Fairness is not our goal, our core goal is to limit expensive requests and make cluster more robust.Under normal circumstances, non-expensive requests will not be subject to any QoS rule.
- WATCH requests are out of scope.
- This Proposal will not attempt auto-tuning the QoS Rule. Instead the administrator will configure the QoS rule via QoS API.
Future Goals
- Support to match large traffic and high latency requests.
- Implement the QoS Watch command to help users to set QoS Rules.
- Automatically recognize the expensive request and limit the rate appropriately to prevent etcd from being unavailable.
Alternative Solution
Priority and Fairness & Event Ratelimiter (only for k8s apiserver)
“API Priority And Fairness” is a new alpha feature in Kubernetes 1.18. Priority And Fairness permits cluster administrators to divide the concurrency of the control plane into different weighted priority levels. Based on it, we can issue rate-limiting policies for LIST operations targeting users, namespaces, and resources.
For example, k8s newbies have written tens of thousands of CRDs in a namespace. In order to prevent potential LIST operations from affecting the stability of the cluster, we can set the number of concurrent requests based on P&R, but the disadvantage is that apiserver does not know how many resources that etcd will return. if the user cleans up most of the Resources, the administrator also needs to manually increase the number of concurrent requests for this resource.(please correct me if i am wrong).
in etcd QoS Feature, The rate limit will take effect only when NumberOfKeyScan is greater than a higher threshold. Therefore, if a client lists resources through the API without paging, even if the API Server allows a large number of concurrent requests, etcd will limit the rate.
Another problem that needs to be solved is the k8s event.
“EventRateLimit” is a new alpha admission controller in Kubernetes 1.13.it can mitigate the problem where the API server gets flooded by event requests.
in etcd QoS Feature, The rate limit will take effect when PercentOfStorageQuotaUsed is greater than a higher threshold. If necessary,we can even refuse to write events when the number of events is greater than the threshold.
These will be a complement to P&R capabilities.
P&R is only for k8s apiserver, clients in other scenarios (such as configuration center, service discovery and scheduler services) also have the slowquery problem. In kubernetes,In order to avoid list resources, each component has done a lot of optimization and speed limit,but other clients do not have it, so slow queries are very common.
QoS based on gRPC Proxy
Some companies, such as Alibaba, implement the etcd QoS Feature at the etcd proxy layer, it is not in the server. The advantage is that it is easy to develop and maintain and it allows experimentation without changing the etcd server binary. The disadvantage is that one more component is introduced, and the availability of etcd may decrease.
Most users do not use proxy, and at the same time, we cannot estimate the cost of a query request in proxy and don’t know the percentage of db size used, etc, which will lead to poor QoS rule expansion.
QoS based on etcd
Next, I will introduce a solution based on etcd to implement QoS, which has the feature of flexibility and strong scalability.
This Feature will be introduced behind an experimental flag. If you do not enable the experimental flag, etcd QoS API is not available and will not create related buckets for QoS in boltdb.
In order to ensure its accuracy, we will implement unit testing, e2e testing, integration testing, and the most important thing is the accuracy of the speed limit. We can implement a mini-benchmark, run multiple test cases, and obtain the mean, standard deviation, and variance. Then judge whether the QPS is accurate and the error is within the allowable range based on variance.
Proposal
Identify Expensive Request
Expensive requests can be divided into two categories, one is cpu resource-consuming and the other is high traffic requests.
● CPU resource consumption type
CPU resource consumption types include full keyspace fetch and a large number of keys queries,etc. On the one hand, it can be judged by the number of keys scanned from the kvindex tree..
revpairs := tr.s.kvindex.Revisions(key, end, rev)
tr.trace.Step("range keys from in-memory index tree")
if len(revpairs) == 0 {
return &RangeResult{KVs: nil, Count: 0, Rev: curRev}, nil
}
if ro.Count {
return &RangeResult{KVs: nil, Count: len(revpairs), Rev: curRev}, nil
}
On the other hand, Identify expensive cpu intensive requests through user experience or RPC latency data.
such as the gRPC Authenticate Method, it will call auth’s bcrpt.CompareHashAndPassword for password verification, which will consume a lot of CPU. There is no QPS limit, it is easy to make CPU high load (8 core and 32G machine, only supports 200 qps).
● High traffic request type
The high traffic request type will often cause the machine bandwidth to be exhausted, which will seriously cause etcd OOM, such as list all pods, list all configmap, list all crd. This scenario can be identified according to the size of the request packet and the response packet.
Queue Discipline Kind
QDisc(queue discipline) is the core of QoS and traffic control. It determines how to handle it when etcd server receives a request.
There are three main methods of traffic control:
- Shaping Speed limit, the rate of requests to etcd servers is controlled below a threshold.
- Scheduling According to the importance of etcd rpc requests, it can be divided into different priority levels. etcd server prioritizes high-priority requests, and low-priority requests are processed last. For example, slow query and high traffic requests have the lowest priority, other requests have the highest priority or are not subject to flow control at all.
- Discard If the requested QPS exceeds the threshold, a rate limit error is returned to the client.
In etcd, we use the shaping algorithm. The shaping algorithms suitable for etcd scenarios mainly include the following three:
● Token bucket filter
● leaky bucket filter
● max inflight request filter
QoS Class
We use the QoS Class to indicate what queue discipline is used for flow control. Each class corresponds to a unique class name (set by the user).
The syntax for adding a QoS Class is as follows:
etcdctl qos class [add/del/get/list/update] name --qdisc-kind OPTIONS
For example, add a class named slow-query, use the token bucket filter algorithm to limit the speed, and it allows bursts of up to ‘burst’ to exceed the QPS, while still maintaining a moothed qps rate of ‘qps’.
etcdctl qos class add slow-query --qdisc-kind tbf --qps 10 --burst 12
Add a class named high-traffic, use the max inflight request filter algorithm, and the maximum inflight request is allowed to be 5.
etcdctl qos class add high-traffic --qdisc-kind maxinflight --num 5
By the way, the following QoS rule will use the above queue class name.
QoS Rule
We use QoS rules to match inbound requests, which can match the call source of the request, key prefix, requested operation, and when the specified conditions are met, and then associate the request to a queue class for flow control.
type Subject struct {
// User is the caller of user name(such as cert common name)
User string
// ClientIp is the caller of source ip.
ClientIp string
}
type QoSRule struct {
// QClassName indicates which queue class is used for flow control.(such as high-traffic,slow-query)
QClassName string
// Priority is used to choose among the QoS Rules that match a given request.
// it indicates the priority of this rule,when a request satisfies multiple rules,
// the rule with the highest priority is selected.
// Priority value must be ranged in [1,100].
Priority int
//Subjects is the list of normal user, clientip that this rule cares about.
Subject []Subject
// PrefixPaths is a list of matching key prefix
// such as registry/events
PrefixPaths []string
// Ops is a list of matching operations(RequestRange,RequestPut,RequestDelete), and so it can support txn.
Ops []string
// Conditions is a list of matching conditions.
Conditions []Condition
}
type ConditionKind string
const (
ConditionKindPercentDBQuotaUsed ConditionKind = "PercentOfStorageQuotaUsed"
ConditionKindNumberOfScanKey ConditionKind = "ScanKeyNum"
ConditionKindRequestSize ConditionKind = "RequestSize"
ConditionKindResponseSize ConditionKind = "ResponseSize"
ConditionKindTotalTrafficSize ConditionKind = "TotalTraffic"
ConditionKindRequestLatency ConditionKind = "RequestLatency"
)
type Condition struct {
// Kind specify condition kind name,for example,ConditionKindPercentDBQuotaUsed.
Kind ConditionKind
// Threshold is a comparison value for whether the condition is met.
// For Example, If Kind is ConditionKindPercentDBQuotaUsed,
// and when PercentOfStorageQuotaUsed > Threshold,the rule will take effect.
Threshold float64
}
The QoS Rule has the following field and attribute:
● QClassName
QClassName indicates which queue class is used for flow control (for example, the class we created above,slow-query,high-traffic)
● Priority
priority is used to choose among the QoS Rules that match a given request.it indicates the priority of this rule,when a request satisfies multiple rules,the rule with the highest priority is selected. If multiple QoS Rules with equal priority match the same request, the one with a lexicographically smaller name will win, but it’s better not to rely on this, and instead to ensure that no two QoS Rule have the same priority. I expect that under normal circumstances, the number of QoS rules is very small, not more than 100,so priority value must be ranged in [1,100].
● Subject
Subjects is the list of normal user, clientip that this rule cares about.
● Prefix key path
PrefixPaths is a list of matching key prefixes,such as registry/events.
● Ops
Ops is a list of matching operations(RequestRange,RequestPut,RequestDelete,Authenticate), and so it can support txn.
QoS Rule also has the following conditional attributes:
● condition/PercentOfStorageQuotaUsed
Support to match inbound requests when PercentOfStorageQuotaUsed(backendDBInUse / backendDBQuota) is greater than the threshold.
● condition/traffic(implement later)
Support to match high traffic requests when rpc requests traffic(request,response,sum of request and response) is greater than the threshold.we can track expensive requests' overheads by caching their hashes or estimating based statistical data.
● Condition/numberOfScanKey
Support to match slow query read requests when the number of keys scan is greater than the threshold.we can track expensive requests' overheads by caching their hashes or estimating based statistical data.
● Condition/latency(implement later)
Support to match high latency requests when rpc latency is greater than the threshold.we can track expensive requests' overheads by caching their hashes or estimating based statistical data.
For example one,if we want to limit TXN(RequestOp_RequestPut) requests to less than 2(qps) when ‘percentOfStorageQuotaUsed > 90% and prefix key is registry/events, it can describe as follows:
// create queue class for event
etcdctl qos class add event --qdisc-kind lbf --qps 2
// create qos rule to match k8s event write request
etcdctl qos rule add rule-event
--qclassName event
--priority 9
--prefixPaths registry/events
--ops RequestPut
--condition-kind ConditionKindPercentDBQuotaUsed
--condition-threshold 0.9
If we build in this QoS rule in etcd,we can prevent etcd from being unwritable in abnormal situations.
For example two,if we want to limit slow query(Range) requests to less than 10(qps),burst(12) when ‘NumberOfScanKeyNum > 1000 and prefix key is registry/pods, it can describe as follows:
// create queue class for slowlog
etcdctl qos class add slow-query --qdisc-kind tbf --qps 10 --burst 12
// create qos rule to match slowquery request
etcdctl qos rule add rule-slowlog
--qclassName slow-query
--priority 10
--ops Range
--prefixPaths registry/pods
--condition-kind NumberOfScanKeyNum
--condition-threshold 1000.0
If we build in this QoS rule in etcd,we can avoid slow query results in etcd oom or costing too much memory(#issue12256).
Add a QoS rule as shown in the example above. we will implement the QoS Rule API of add, get, update, and delete and related etcdctl QoS Rule command.
How to estimate NumberOfKeyScan of a read request
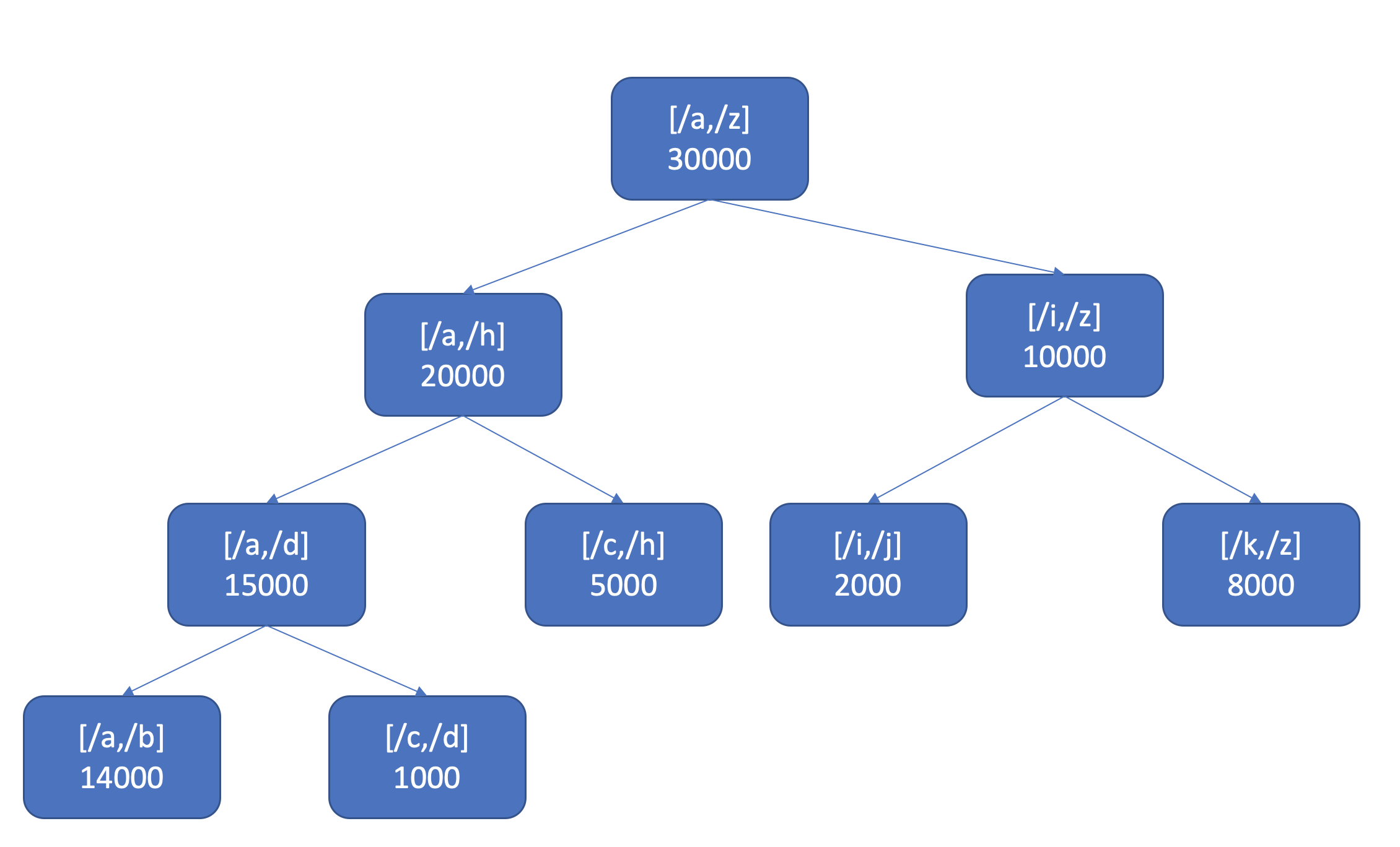
We can use the segment/interval tree to count the number of keys within the query range. segment tree, also known as a statistic tree, is a tree data structure used for storing information about intervals, or segments. For each interval we store the number of keys in this interval.
For example, in the figure below, when we query a range [/a,/b], we can quickly get the number of keys.In order to control the memory overhead of segment tree, we need to introduce random algorithms for sampling statistics(to do,POC).
Through this statistical information, we can predict slow queries and limit the speed in advance.
Track Expensive Request
How to record whether a request is a cpu resource-consumable and a high-traffic type with controllable memory overhead? The following are my thoughts. When a request is received, the processing steps are as follows:
- When the server starts, create a fixed size LRU Cache.
- When receiving a read request, calculate the hash value of the request.
- Attempt to find out from LRU Cache whether it exists, if it exists, and meet at least one rule of QoS Rule, then select the rule with the highest priority to execute flow control. If it is speed limited, return ErrLimitRequest to the client.
- Execute the rpc interface.
- After execution, if the rpc request already exists in the LRU queue or its runtime information (latency/traffic/scanKeyNum, etc.) meets at least one QoS rule, the runtime information is updated to the LRU cache queue.
Instruct users to set QoS Rules(Future Goal)
When the etcd machine bandwidth and memory are about to be exhausted, how to quickly locate which request? (of course, metric monitoring and logging can also play a role,but not so fast and precise). And set reasonable QoS rules to limit it? Or see which requests are affected by QoS rules?
We can design and implement a QoS monitor command(Streaming RPC) to collect and filter rpc requests in real time, and return the rpc requests that meet the conditions.
The qos monitor syntax is as follows:
etcdctl qos monitor --type (latency/traffic/scanKeyNum) --threshold --limit (<100)
Types support the following:
scanKeyNum
Specify request scanKeyNum,when the request scanKeyNum is greater than the threshold, at most limit requests are collected.
rpc latency
Specify rpc latency,when the rpc latency is greater than the threshold, at most limit requests are collected.
rpc traffic
Specify rpc traffic. When the rpc packet size is greater than the threshold, maximum limit requests are collected.
Thoughts on decomposing the rules(ptabor)
The goal of this section is to discuss/understand what types of information build a rule. This will allow to shape the proper API / protos that are expandable and easy to understand for the users:
Example: “Each user can send List requests that scan 10000 keys in 1-minute windows. “
Selector (“List requests”):
- Is defining which requests are subject to the rule. The request can be identified by:
- Service Name
- Method Name
- User Name (identity of sender)
- Key-range (for majority of requests). Please note that the rules of matching key-range by request depend on the request type. In practice we should check if the ranges overlap:
- Watch /foo/… should match the rule for range “/foo/bar/…” as the ranges overlap.
- Watch /foo/bar/.. . should match the rule for “/foo/…” as the ranges overlap.
- Put /foo/x should not match the rule for range “for/bar/…” as the ranges do not overlap.
- Stretch: Number of retry of this very request
- Stretch: Caller IP address.
Cost
- Cost (“that scan … keys”):
- Count of requests (aka QPS)
- Count of ‘failed requests’ (‘if the user is sending bad request they should be throttled more than the successful ones’)
- Sum of incoming request sizes
- Sum of generated traffic (incoming request_sizes + response_sizes).
- requires some prediction of a response_size
- Number of scanned keys [requires prediction]
- Total wall-time spent on serving requests [requires prediction]
- Total cpu-time spent on serving the requests [requires prediction]
Accounting Group (“per each user”):
By default we have a limit per-rule, i.e. per-server. Server either accepts the requests that match Selector or refuse them, but makes the decision based on a ‘single’ state. But Quality of Service solutions want to protect one ‘user’ / ‘type of calls’ / ‘key-space’ from others. So by accounting we might express that the rules are evaluated per some properties like: User IP
Key-space pattern
Note that if we have 2 users: Alice and Bob we might simulating “grouping” by defining 2 rules:
Alice can send 10 qps. Bob can send 10 qps. If the administrator does not want to reconfigure the rules every time they add a new user, they need some form of grouping setting. I guess its low-priority feature, but adding it for completeness.
Aggregation method:
- Running windows of given size: e.g. 10000 “units of cost” in 100s. (please not that it’s different from 100req /s ) as the former allows bursts to 10k
- Token bucket filter (not sure if it can be applied to different costs)
- leaky bucket filter, etcd. (not sure if it can be applied to different costs)
- In flight counter (when requests starts we bump the counter, if finishes we decrease),
- In practice applied to the ‘count’ cost. In theory we could say: we admit request of summarized size up to 1MB concurrently.
Limit: e.g. 10000 (“units of costs” aggregated using “aggregation method” per “Accounting group” of requests that match the “selector”) Metrics To implement metrics, report the number of requests that are speed-limited and the number of expensive requests.
Alternative Solution
FAQ
1、How to track expensive requests and make a decision on whether to limit a request?
Yue9944882: Not knowing the time/cpu/memory/traffic size consumption unless the request’s finished,kubernetes uses an “estimated” cost.
we can track expensive requests’ overheads by caching their hashes or estimating based statistical data.
2、How to shape the traffic?
Fairness is not our goal, our core goal is to limit expensive requests.meanwhile,etcd node does not frequently adjust the size of cpu and memory resources and non-expensive requests will not be subject to any QoS rule. So we use multiple rate limiters to shape the expensive traffic, not k8s fair queue.
3、How to support txn?
We should match operations not gRPCMethod.
4、Should we need to assign a priority to each rule? How to choose a rule if multiple rules have the same priority?
Yes, the rule with higher priority is the strictest. If multiple QoS Rules with equal priority match the same request, the one with a lexicographically smaller name will win, but it’s better not to rely on this, and instead to ensure that no two QoS Rule have the same priority.
Wojtek-t: I would say that this should then be validated during creation (i.e. ensure that no two rules with the same priority can match the same request).
5、How to measure QoS Feature without affecting stability and performance?
6、Should we support custom rules?
Wojtek-t: I’m also slightly against custom rule - either we already have usecase for rules, or we don’t (and then don’t overengineer).
Done, we no longer need custom rules, QoS Rules can match and meet the needs of various scenarios.
7、How to Distinguish the identity of Callers?
User name/(auth info),client ip
8、How we’re going to test: correctness testing, scale testing, performance impact?
9、Which rule should we make it built-in(if users enable qos feature)?
We can build in slow query rules into etcd when the user enables the qos feature. For example, add a rule to limit slow query(Range) requests to less than 10(qps),burst(12) when ‘NumberOfScanKeyNum > 10000:
// create queue class for slowlog
etcdctl qos class add slow-query --qdisc-kind tbf --qps 10 --burst 12
// create qos rule to match slowquery request
etcdctl qos rule add rule-slowlog
--qclassName slow-query
--priority 10
--ops Range
--condition-kind NumberOfScanKeyNum
--condition-threshold 1000.0
10、What is an expensive request?
Large request and response packets, read requests that scan a large number of keys, Authenticate may be expensive requests.
Future Work
First, We can Support to match large traffic and high latency requests based on community feedback and implement QoS Watch to help users to set QoS Rules.
Secondly,Similar to the function of redis latency / memory doctor, intelligent optimization suggestions are given.
Finally,Automatically recognize the expensive request and limit the rate appropriately to prevent etcd from being unavailable.
Related Work
- Kubernetes Priority and Fairness KEP
- Kubernetes Priority and Fairness Documentation
Related Issues
- https://github.com/etcd-io/etcd/issues/8483
- https://github.com/etcd-io/etcd/issues/12164
- https://github.com/etcd-io/etcd/issues/10084
- https://github.com/etcd-io/etcd/issues/7381
- https://github.com/etcd-io/etcd/issues/12256